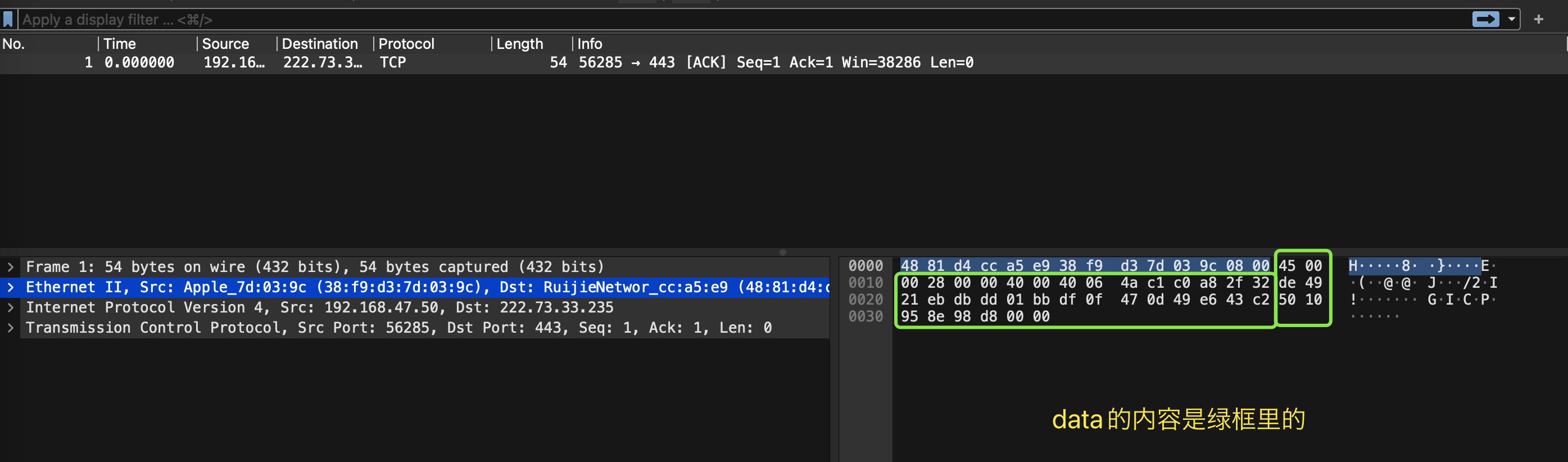
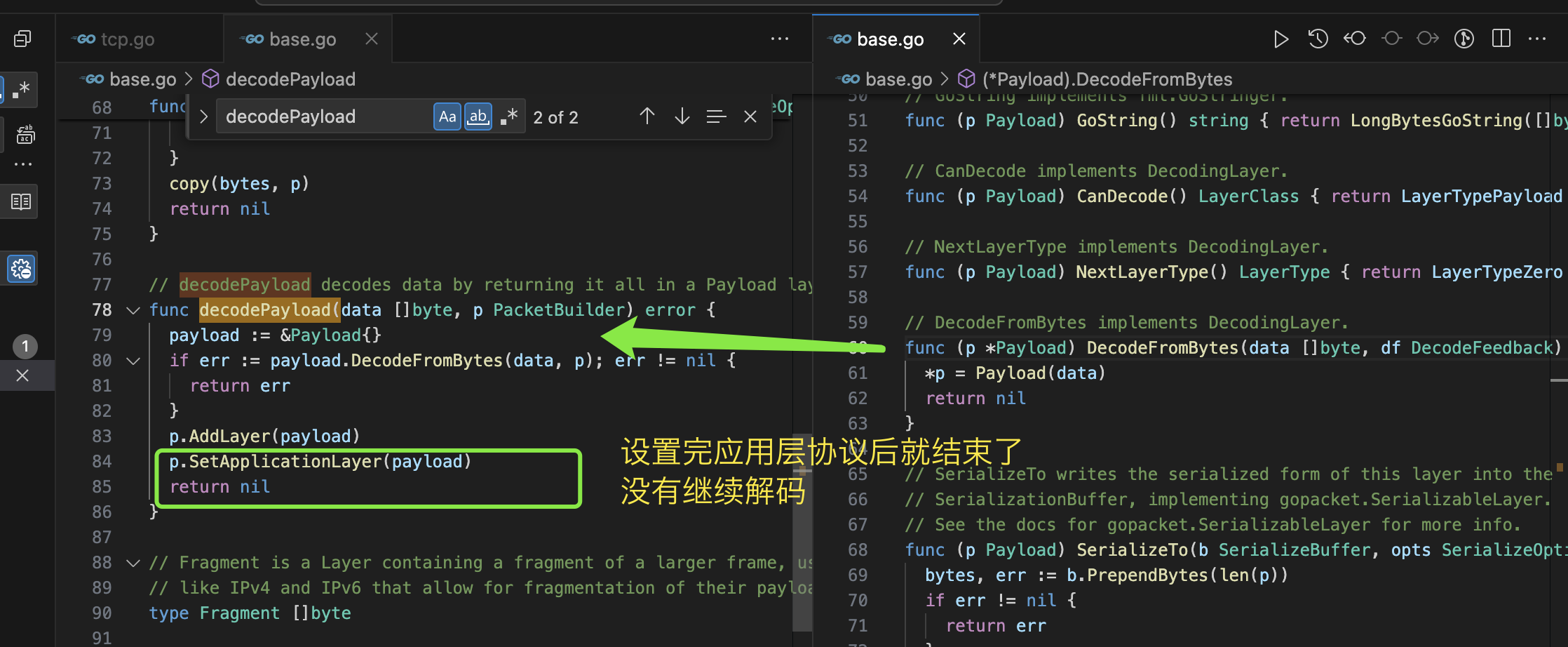
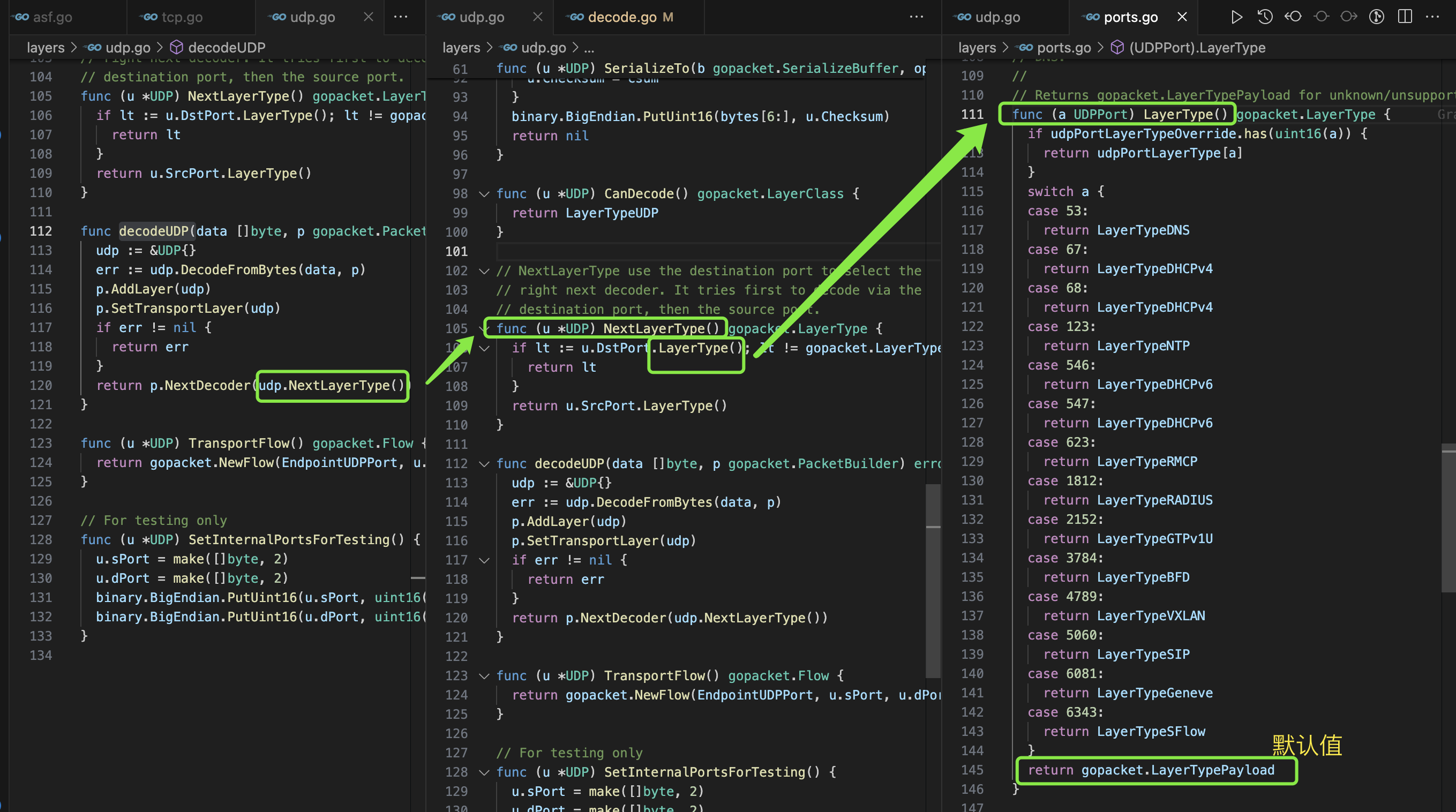
type PacketDataSource interface { // ReadPacketData returns the next packet available from this data source. // It returns: // data: The bytes of an individual packet. // ci: Metadata about the capture // err: An error encountered while reading packet data. If err != nil, // then data/ci will be ignored. ReadPacketData() (data []byte, ci CaptureInfo, err error) }
ifc, err := net.InterfaceByName(device) if err != nil { // The device wasn't found in the OS, but could be "any" // Set index to 0 p.deviceIndex = 0 } else { p.deviceIndex = ifc.Index }
p.nanoSecsFactor = 1000// 直接翻译为纳秒因子
// Only set the PCAP handle into non-blocking mode if we have a timeout // greater than zero. If the user wants to block forever, we'll let libpcap // handle that. // 仅当超时大于零时,才将 PCAP 句柄设置为非阻塞模式。 如果用户想要永远阻塞,我们会让 libpcap 来处理。 if p.timeout > 0 { if err := p.setNonBlocking(); err != nil { p.pcapClose() returnnil, err } }
// set after we have call waitForPacket for the first time var waited bool
// stop 为 0 表示没有停止,使用原子读取 // 只要 stop 为 0 的时候就循环执行 for atomic.LoadUint64(&p.stop) == 0 { // try to read a packet if one is immediately available // pcapNextPacketEx 尝试从底层的 libpcap 读取数据包 result := p.pcapNextPacketEx()
switch result { case NextErrorOk: // 获取数据包的时间戳中的秒数部分,并将其赋值给 sec 变量。 sec := p.pkthdr.getSec() // p.pkthdr.getUsec() 方法获取数据包的时间戳中的微秒数部分 // convert micros to nanos // 将毫秒转换为纳秒 nanos := int64(p.pkthdr.getUsec()) * p.nanoSecsFactor
returnnil case NextErrorNoMorePackets: // 没有更多的数据包可读了 // no more packets, return EOF rather than libpcap-specific error return io.EOF case NextErrorTimeoutExpired: // we've already waited for a packet and we're supposed to time out // // we should never actually hit this if we were passed BlockForever // since we should block on C.pcap_next_ex until there's a packet // to read. if waited && p.timeout > 0 { return result }
// wait for packet before trying again p.waitForPacket() waited = true default: return result } }
// stop must be set return io.EOF }
// 其他补充:golang 一般会在栈上分配内存,因为栈上内存的分配和回收更快 func(p *Handle) pcapNextPacketEx() NextError { // This horrible magic allows us to pass a ptr-to-ptr to pcap_next_ex // without causing that ptr-to-ptr to itself be allocated on the heap. // Since Handle itself survives through the duration of the pcap_next_ex // call, this should be perfectly safe for GC stuff, etc. // 强制类型转换 // pcap_next_ex 是 libpcap 的从网络接口中读取下一个数据包的函数 // 由于 pcap_next_ex 函数的参数需要传递指向指针的指针, // 为了避免在堆上分配内存,这段代码使用了一种技巧来传递指针的地址而不会分配额外的内存。 return NextError(C.pcap_next_ex_escaping( // p.cptr 是 Handle 结构中的一个指向 pcap_t 结构的指针 p.cptr, // 使用unsafe.Pointer 先转换为 unsafe.Pointer 类型, // 然后使用 uintptr 将这些指针转换为整数。 // C.uintptr_t 将整数转换为 C 语言中的 uintptr_t 类型。
funcNewPacket(data []byte, firstLayerDecoder Decoder, options DecodeOptions) Packet { // NoCopy 表示是否直接操作数据包的原始数据,操作原始数据可能会影响原始包 if !options.NoCopy { dataCopy := make([]byte, len(data)) copy(dataCopy, data) data = dataCopy } if options.Lazy { p := &lazyPacket{ packet: packet{data: data, decodeOptions: options}, next: firstLayerDecoder, } p.layers = p.initialLayers[:0] // Crazy craziness: // If the following return statemet is REMOVED, and Lazy is FALSE, then // eager packet processing becomes 17% FASTER. No, there is no logical // explanation for this. However, it's such a hacky micro-optimization that // we really can't rely on it. It appears to have to do with the size the // compiler guesses for this function's stack space, since one symptom is // that with the return statement in place, we more than double calls to // runtime.morestack/runtime.lessstack. We'll hope the compiler gets better // over time and we get this optimization for free. Until then, we'll have // to live with slower packet processing. // 设置为 lazy 则直接返回 return p } p := &eagerPacket{ packet: packet{data: data, decodeOptions: options}, } // layers 置为空 p.layers = p.initialLayers[:0] p.initialDecode(firstLayerDecoder) return p }
type Decoder interface { // Decode decodes the bytes of a packet, sending decoded values and other // information to PacketBuilder, and returning an error if unsuccessful. See // the PacketBuilder documentation for more details. Decode([]byte, PacketBuilder) error }
// DecodeOptions tells gopacket how to decode a packet. type DecodeOptions struct { // Lazy decoding decodes the minimum number of layers needed to return data // for a packet at each function call. Be careful using this with concurrent // packet processors, as each call to packet.* could mutate the packet, and // two concurrent function calls could interact poorly. Lazy bool // NoCopy decoding doesn't copy its input buffer into storage that's owned by // the packet. If you can guarantee that the bytes underlying the slice // passed into NewPacket aren't going to be modified, this can be faster. If // there's any chance that those bytes WILL be changed, this will invalidate // your packets. NoCopy bool // SkipDecodeRecovery skips over panic recovery during packet decoding. // Normally, when packets decode, if a panic occurs, that panic is captured // by a recover(), and a DecodeFailure layer is added to the packet detailing // the issue. If this flag is set, panics are instead allowed to continue up // the stack. SkipDecodeRecovery bool // DecodeStreamsAsDatagrams enables routing of application-level layers in the TCP // decoder. If true, we should try to decode layers after TCP in single packets. // This is disabled by default because the reassembly package drives the decoding // of TCP payload data after reassembly. DecodeStreamsAsDatagrams bool }
// lazyPacket does lazy decoding on its packet data. On construction it does // no initial decoding. For each function call, it decodes only as many layers // as are necessary to compute the return value for that function. // lazyPacket implements Packet and PacketBuilder. type lazyPacket struct { packet next Decoder }
// packet 实现了 gopacket.PacketBuilder interface // packet contains all the information we need to fulfill the Packet interface, // and its two "subclasses" (yes, no such thing in Go, bear with me), // eagerPacket and lazyPacket, provide eager and lazy decoding logic around the // various functions needed to access this information. type packet struct { // data contains the entire packet data for a packet data []byte // initialLayers is space for an initial set of layers already created inside // the packet. // 存储已经创建好了的各层数据 initialLayers [6]Layer // layers contains each layer we've already decoded layers []Layer // last is the last layer added to the packet last Layer // metadata is the PacketMetadata for this packet metadata PacketMetadata
decodeOptions DecodeOptions
// Pointers to the various important layers link LinkLayer network NetworkLayer transport TransportLayer application ApplicationLayer failure ErrorLayer }
func(p *lazyPacket) Layer(t LayerType) Layer { for _, l := range p.layers { // 数据包之前已经被解码了的情况下,遍历已经解码了的各层 // 一旦发现需要的数据层,立刻返回 if l.LayerType() == t { return l } } numLayers := len(p.layers) // p.next 为空的时候,表示所有能解码的都解码完毕了 for p.next != nil { // 只解码一层,不会包整个包都解码完分析完 p.decodeNextLayer() for _, l := range p.layers[numLayers:] { if l.LayerType() == t { return l } } numLayers = len(p.layers) } returnnil }
func(p *lazyPacket) decodeNextLayer() { if p.next == nil { return } d := p.data if p.last != nil { d = p.last.LayerPayload() } next := p.next p.next = nil // We've just set p.next to nil, so if we see we have no data, this should be // the final call we get to decodeNextLayer if we return here. iflen(d) == 0 { return } defer p.recoverDecodeError() err := next.Decode(d, p) if err != nil { p.addFinalDecodeError(err, nil) } }
type PacketBuilder interface { DecodeFeedback // AddLayer should be called by a decoder immediately upon successful // decoding of a layer. AddLayer(l Layer) // The following functions set the various specific layers in the final // packet. Note that if many layers call SetX, the first call is kept and all // other calls are ignored. SetLinkLayer(LinkLayer) SetNetworkLayer(NetworkLayer) SetTransportLayer(TransportLayer) SetApplicationLayer(ApplicationLayer) SetErrorLayer(ErrorLayer) // NextDecoder should be called by a decoder when they're done decoding a // packet layer but not done with decoding the entire packet. The next // decoder will be called to decode the last AddLayer's LayerPayload. // Because of this, NextDecoder must only be called once all other // PacketBuilder calls have been made. Set*Layer and AddLayer calls after // NextDecoder calls will behave incorrectly. NextDecoder(next Decoder) error // DumpPacketData is used solely for decoding. If you come across an error // you need to diagnose while processing a packet, call this and your packet's // data will be dumped to stderr so you can create a test. This should never // be called from a production decoder. DumpPacketData() // DecodeOptions returns the decode options DecodeOptions() *DecodeOptions }
type Decoder interface { // Decode decodes the bytes of a packet, sending decoded values and other // information to PacketBuilder, and returning an error if unsuccessful. See // the PacketBuilder documentation for more details. Decode([]byte, PacketBuilder) error }